
Picture

Emmanuel Ponsot
Laboratoire des Systèmes Perceptifs
Post-doctorant·e
29 rue d'Ulm
75005 Paris France
Laboratoire
LSP
Equipe
Vision
Email
Publications sélectionnées
RESEARCH INTERESTS
I am interested in understanding how the human brain processes complex sensory signals such as speech and visual scenes, at both sensory and cognitive levels. Based on an interdisciplinary approach combining signal-processing techniques, neurophysiology, psychophysics and computational modelling, my goal is to provide a clear mechanistic account of various perceptual processes. This research is conducted in the lab with healthy individuals and in clinical contexts to better understand how different disorders (e.g. sensorineural hearing loss, stroke) impact the different stages of sensory processing.
Example #1: How do we extract speech features from noise?
As we age, almost all of us will complain about increased difficulty to communicate in noisy environments. An important issue is why some individuals, even without measurable loss in audibility, experience more difficulties than others. Speech in noise understanding relies on the ability of our auditory system to extract relevant spectro-temporal modulations from noise, but the mechanisms underlying this processing remain poorly characterized.
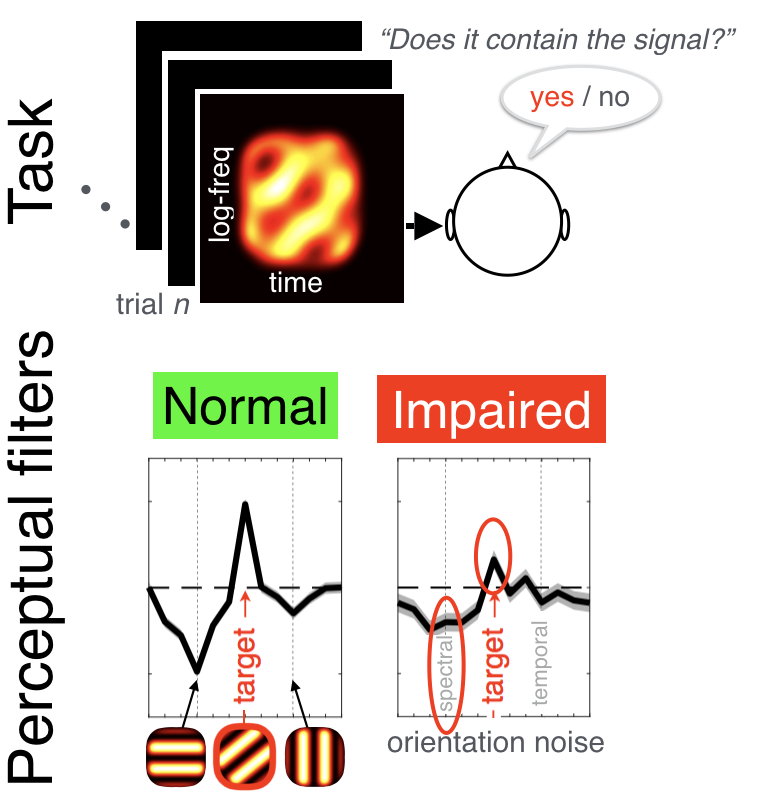
Inspired from visual studies, we have developed a psychophysical procedure to estimate spectrotemporal modulation filtering behaviorally using a reverse correlation approach. We measure listeners' perceptual filters task for detecting a specific target, i.e. how they filter out other modulations in the stimulus. Our results show on average that, as compared to normal-hearing listeners (left), hearing-impaired listeners (right) exhibit an overall reduced amplitude to extract the target. A closer look at individual patterns show various behaviors, that were not predictable from audiometric profiles. Using physiologically-plausible auditory models, we seek to determine where and how these differences emerge along the auditory pathway. Overall, this approach should help us to disentangle the various sources of supra-threshold auditory impairment and determine their role for speech-in-noise perception.
Example #2: How do we infer social and emotional meaning from speech prosody?
Beyond words, speech carries a lot of information about a speaker through its prosodic structure. Humans have developed a remarkable ability to infer others’ states and attitudes from the temporal dynamics of the different dimensions of speech prosody (i.e. pitch, intensity, timbre, rhythm). However, we still do not have a computational understanding of how high-level social or emotional impressions are built from these low-level dimensions. We recently developed a data-driven approach combining voice-processing techniques (using a specifically-designed audio software) and psychophysical reverse-correlation methods to expose the mental representations or ‘prototypes’ that underlie such inferences in speech.
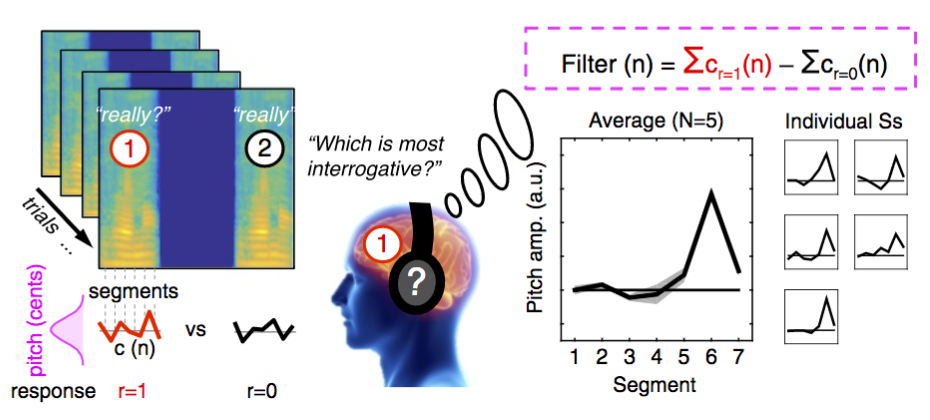
In particular, we have investigated how intonation drives social traits in speech. We have been able to demonstrate the existence of robust and shared mental representations of trustworthiness and dominance of a speaker’s voice. This approach offers a principled way to reverse-engineer the algorithms the brain uses to make high-level inferences from the acoustical characteristics of others’ speech. It holds promise for future research seeking to understand why certain emotional or social judgments differ across cultures and why these inferences may be impaired in some neurological disorders. We are currently running experiments in a clinical context to characterize prosody processing deficits in patients after stroke. Our goal is to develop individualized rehabilitation strategies based on the understanding of how and where their processing is impaired.
SCIENCE COMMUNICATION
A video made by CNRS Images explaining the approach taken in our recent paper to uncover the social code of speech prosody.
