Recherche
28 mars 2023
Mis à jour
30 mars 2023LSP
Notre cerveau anticipe le sens des mots pendant l’écoute de la parole
Chaque jour, nous produisons et entendons quelques dizaines de milliers de mots. Ils structurent nos échanges, et bien souvent, notre pensée. Pourtant, la façon dont le tissu neuronal réalise cette prouesse quotidienne reste largement incomprise. Dans une étude récemment publiée dans Nature Human Behaviour, des chercheur.ses de l’INRIA et du Laboratoire des Systèmes Perceptifs à l’ENS ont montré que le cerveau humain non seulement représente et prédit chaque mot, mais anticipe également le sens qu’ils vont produire une fois combiné. Une capacité d’anticipation sémantique qui se démarque des algorithmes actuels.
Des progrès considérables ont récemment été réalisés dans le domaine du traitement du langage naturel : les algorithmes d'apprentissage profond sont de plus en plus capables de générer, de résumer, de traduire et de classer des textes. Pourtant, ces modèles linguistiques ne parviennent toujours pas à égaler les capacités linguistiques des humains.
Les récents développements en intelligence artificielle pourraient bien changer cela: les nouveaux algorithmes de langage tels que Llama (Meta), ChatGPT (OpenAI) ou Bardes (Google) sont désormais capables de générer des textes remarquablement plausibles. Pour cela, ces modèles sont typiquement entraînés à prédire chaque mot d’un texte à partir de ce qui le précède. Par exemple, pour "il était une", le modèle doit prédire que "fois" est plus probable que "table", "chien" ou "panorama". Cette tâche de prédiction du prochain mot est ensuite optimisée ad nauseam, sur des milliards de textes. Et le résultat est étonnant : ces algorithmes deviennent capables de répondre à de nombreuses questions complexes.
Ces modèles traitent-ils le langage comme notre cerveau?
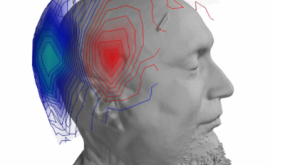
Pour répondre à cette question, Charlotte Caucheteux (Inria, Meta), Alexandre Gramfort (Inria) et Jean-Rémi King (ENS, Meta) ont comparé des algorithmes de langage à notre cerveau, ou plus précisément aux réponses cérébrales enregistrées par imagerie par résonance magnétique (IRMf).
En analysant le cerveau de plus de 300 volontaires lors de l’écoutant d’histoires courtes dans l’IRM, les auteur.es montrent que le cerveau humain non seulement représente et prédit chaque mot, mais anticipe également le sens qu’ils vont produire une fois combiné. Plutôt que de simplement prédire “fois” après avoir entendu “il était une”, notre cerveau anticipe le déroulement d’un conte, même si les mots exacts ne peuvent être précisément connus à l’avance.
Comment un tel résultat est-il révélé?
Lorsque nous écoutons des histoires, les informations sensorielles sont transmises de la cochlée, jusqu’au cortex. De là, les neurones du cortex vont transformer ces informations grâce à une hiérarchie d’aires cérébrales, dont le but est d’identifier les phonèmes, les mots, et ultimement le sens des phrases. Chacune de ces opérations est ainsi liée à une activité cérébrale particulière. De la même manière, un algorithme d’apprentissage profond est composé de neurones artificiels qui s’activent différemment en fonction de ce qu’ils reçoivent en entrée. L’étude consiste ainsi à estimer si ces deux types d’activations – cérébrales ou algorithmiques – sont similaires. En modifiant l’algorithme, les auteu.res peuvent ainsi identifier les représentations, et les prédictions réalisées dans le cerveau à chaque instant.
Une capacité d’anticipation sémantique non encore égalée par l'IA
Cette capacité d’anticipation sémantique se démarque des algorithmes actuels, qui, eux, sont entrainés à prédire chaque mot à partir de ce qui les précède. En revanche, ces résultats confortent la théorie dite du “codage prédictif”, qui propose que le cortex prédit en permanence une "hiérarchie" de représentations : ainsi, les premières aires corticales seraient responsables d’anticiper les phonèmes, et les mots, alors que les aires fronto-pariétales seraient, elles, chargées d’anticiper la sémantique du langage.
Plus généralement, cette découverte montre comment l'intelligence artificielle et les neurosciences se nourrissent mutuellement, et permettent ainsi de mieux comprendre les structures de notre pensée – et de celle des algorithmes.
Bibliographie :
Caucheteux, Gramfort & King (2023). Evidence of a predictive coding hierarchy in the human brain listening to speech, Nat Hum Behav 7, 430–441. doi:10.1038/s41562-022-01516-2Contact :
Jean-Rémi King, Chercheur CNRS I jeanremi.king@gmail.comPOUR EN SAVOIR PLUS
Actualités